Actualizando scraping inicial de airbnb
Ok, cuando inicié el proyecto de scraping de Airbnb (aprox. agosto 2023), Airbnb mandaba datos distintos en la página inicial de un área geográfica, “pintaba” directamente en cards los textos de los listings, pero al día de hoy esto cambió y ahora manda los datos primero en un script en formato json y luego con javascript los pinta en el html de la página. Por la forma en la que hago scraping (requests + BeautifulSoup) tengo que extraer los datos del script/json.
Por tanto, tuve que ver de nuevo cómo se hace el scraping de este nuevo código, por lo que hice la siguiente página openhtml.py, que lee el html del request de una página y procesa los datos, ya con esto se puede integrar de nuevo a esta parte del proyecto.
from bs4 import BeautifulSoup
import os
import json
path_file_ini = './data/pages/1-a040284b-1310-4af7-b429-1039cfd22971.html'
html = ''
listings=[]
if os.path.isfile(path_file_ini):
print("from disk")
with open(path_file_ini, "r", encoding="utf-8") as file:
html = file.read()
soup_html = BeautifulSoup(html, "html.parser")
scripts = soup_html.find_all("script", attrs={"type":"application/json", "id":"data-injector-instances"})
if(len(scripts) >= 1):
node = json.loads(scripts[0].text)
results = node["root > core-guest-spa"][1][1]["niobeMinimalClientData"][1][1]["data"]["presentation"]["staysSearch"]["results"]["searchResults"]
for result in results:
listing = result["listing"]
print(f'{type(listing)} {listing["id"]}')
room = {}
room["id"] = listing["id"]
room["title"] = listing["title"]
room["name"] = listing["name"]
room["roomTypeCategory"] = listing["roomTypeCategory"]
room["latitude"] = listing["coordinate"]["latitude"]
room["longitude"] = listing["coordinate"]["longitude"]
room["rating"] = listing["avgRatingLocalized"]
room["beds"] = ""
if listing["structuredContent"]["primaryLine"] is not None and len(listing["structuredContent"]["primaryLine"]) > 0:
if "body" in listing["structuredContent"]["primaryLine"][0]:
room["beds"] = listing["structuredContent"]["primaryLine"][0]["body"]
if "price" in result["pricingQuote"]["structuredStayDisplayPrice"]["primaryLine"]:
room["price"] = result["pricingQuote"]["structuredStayDisplayPrice"]["primaryLine"]["price"]
else:
if "discountedPrice":
room["price"] = result["pricingQuote"]["structuredStayDisplayPrice"]["primaryLine"]["discountedPrice"]
room["price"] = room["price"].replace('\xa0',' ')
print(room)
listings.append(room)
print(f"\ntotal listings found: {len(listings)}")
Al ejecutar el script genera el siguiente resultado:
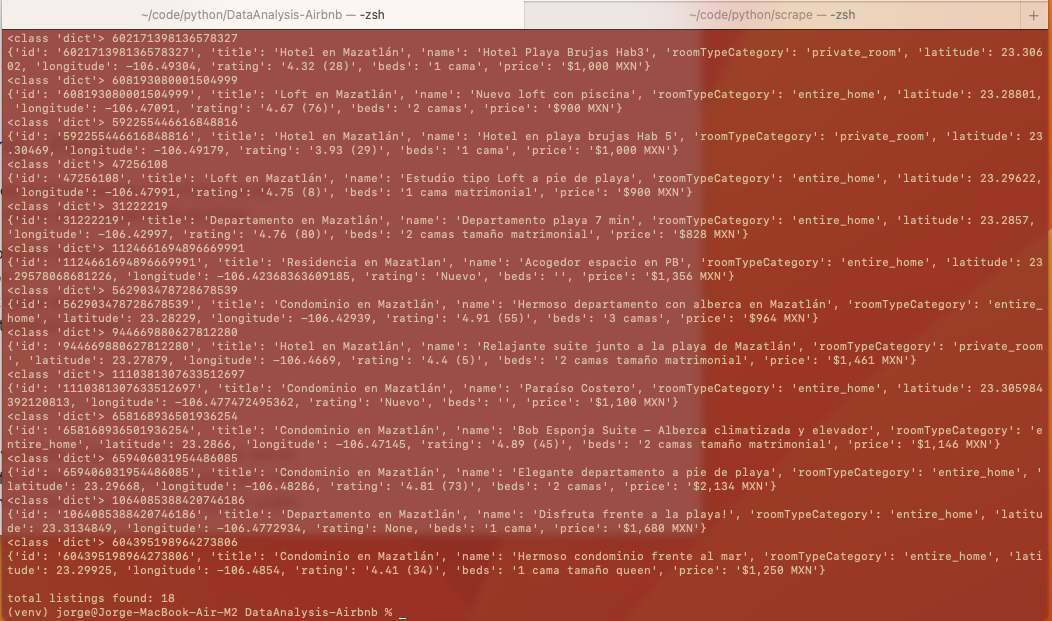
El siguiente paso sobre este html es obtener los links de las demás páginas del “paginado”, hacer el request de esas páginas (máximo 10 páginas) y repetir el scraping sobre esos request; este paso también es nuevo, porque parece que los links de páginas en la páginación vienen también en el json del script, ya veremos…