Scraping mainpage airbnb
En este post explico los primeros pasos para hacer scraping de la página inicial de un área geográfica en Airbnb y extraer los listings que se muestren en esa página.
Scraping de la página inicial de un área geográfica en Airbnb
Manualmente tomé las 4 siguientes urls de base, ya que sé que son las distintas áreas de Mazatlán, así que buscaré en las 10 primeras páginas de estas páginas base.
- https://www.airbnb.mx/s/Mazatlan–Sinaloa–Mexico/
- https://www.airbnb.mx/s/Palos-Prietos–Mazatl%C3%A1n–Sin.–M%C3%A9xico/
- https://www.airbnb.mx/s/Centro–Mazatl%C3%A1n–Sin.–M%C3%A9xico/
- https://www.airbnb.mx/s/cerritos–Mazatl%C3%A1n–Sin.–M%C3%A9xico/
Estableciendo parámetros iniciales del scraping
Sobre estas urls, mando llamar la función extract_listings con la url base y 3 parámetros preestablecidos para la búsqueda:
- fecha: 20 días posteriores a la fecha actual
- 2 huéspedes
- 3 noches
- se establece un máximo de 10 páginas de cada url base para extraer los listings
La página inicial con la que se hace el scraping es como la de la siguiente imagen:
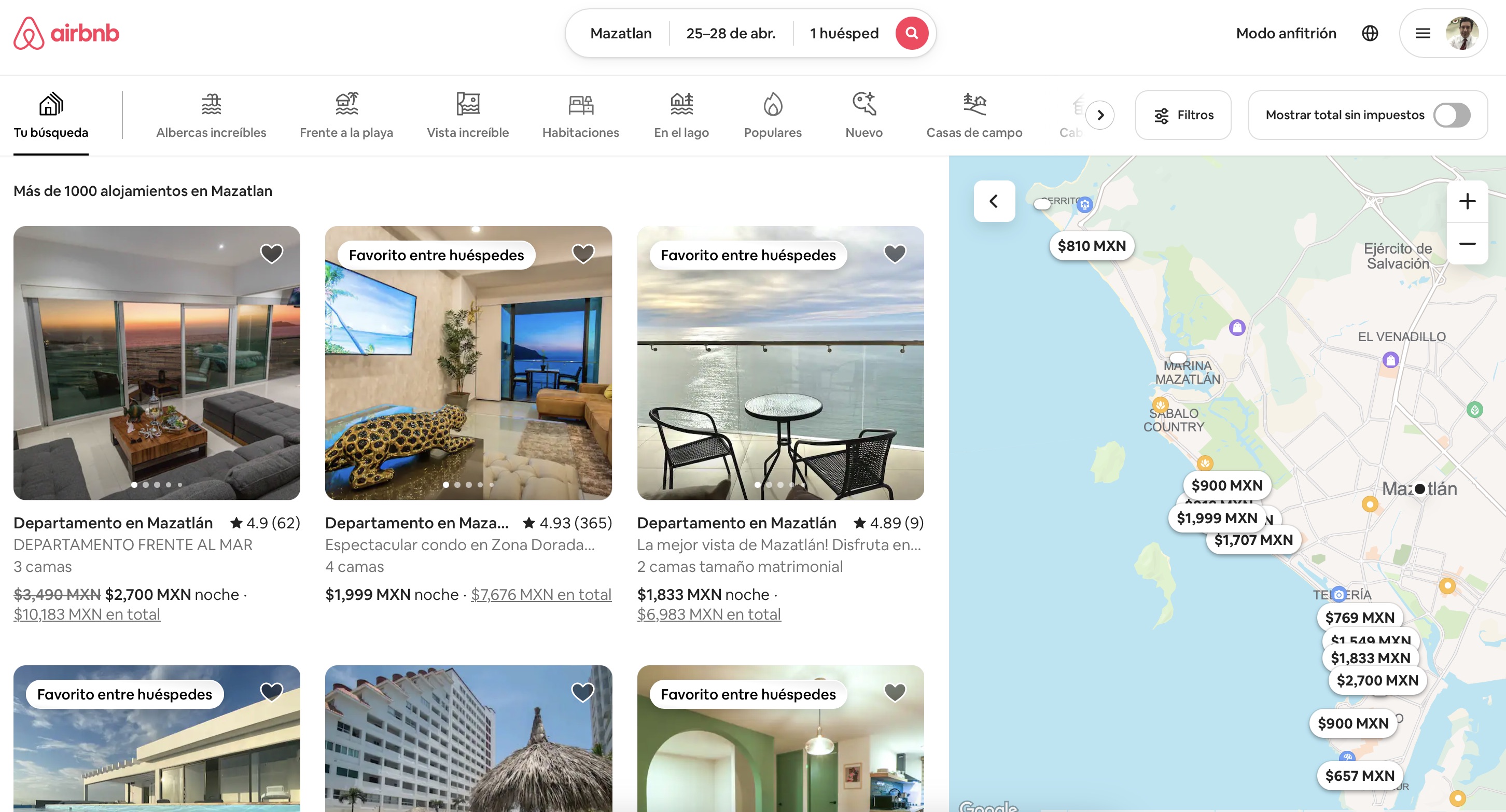
Scraping de página principal de listing de Airbnb
Esta es la función que recibe la URL y hace un scraping de los primeros listings de la página con la función parseCards
def extract_listings(first_page_url, max_pages_scrape):
listings = []
print (f"{first_page_url}")
url = first_page_url
for i in range(1, max_pages_scrape+1):
print(f"getting url {i}/{max_pages_scrape} {url[0:30]}...")
try:
r = requests.get(url)
html = r.text
name_file = f"./data/pages/{i}-{str(uuid.uuid4())}.html"
with open(name_file, "w",encoding="utf-8") as file_json:
file_json.write(html)
print(f"got response: {len(html)/1024} KB")
cards = parseCards(html)
print(f'cards obtained: {len(cards)}')
cards_to_txt(cards)
for item in cards:
listings.append(item)
#get next url
soup = BeautifulSoup(html, 'lxml')
# Use the beautiful soup find function to get the links from the Next symbol html tag.
np = soup.find('a', class_ = "l1ovpqvx c1ytbx3a dir dir-ltr")
if np is None:
break
np = np.get("href")
#create a new link with AirBNB.com as the host and concatenate the next page link.
cnp = "https://www.airbnb.com" + np
url = cnp
wait = random.randint(3,8)
print(f"\nnew url {url[0:50]} w:{wait}")
sleep(wait)
except Exception as inst:
print(f'error getting url...')
print(type(inst))
print(inst.args) # arguments stored in .args
print(inst)
return listings