El archivo con el que se inicia es scrape_page.py, el cual toma 4 links de Airbnb y les hace el scraping tanto a la página inicial como hasta 10 páginas máximo del paginado; se mandan parámetros de 30 días en el futuro, 3 noches de estancia y 2 huéspedes.
Para obtener el código donde residen los datos de los listings, ví que se manda dentro de un script en formato json:
scripts = soup_html.find_all("script", attrs={"type":"application/json", "id":"data-injector-instances"})
Y cada listing se obtiene en el siguiente nodo:
results = node["root > core-guest-spa"][1][1]["niobeMinimalClientData"][1][1]["data"]["presentation"]["staysSearch"]["results"]["searchResults"]
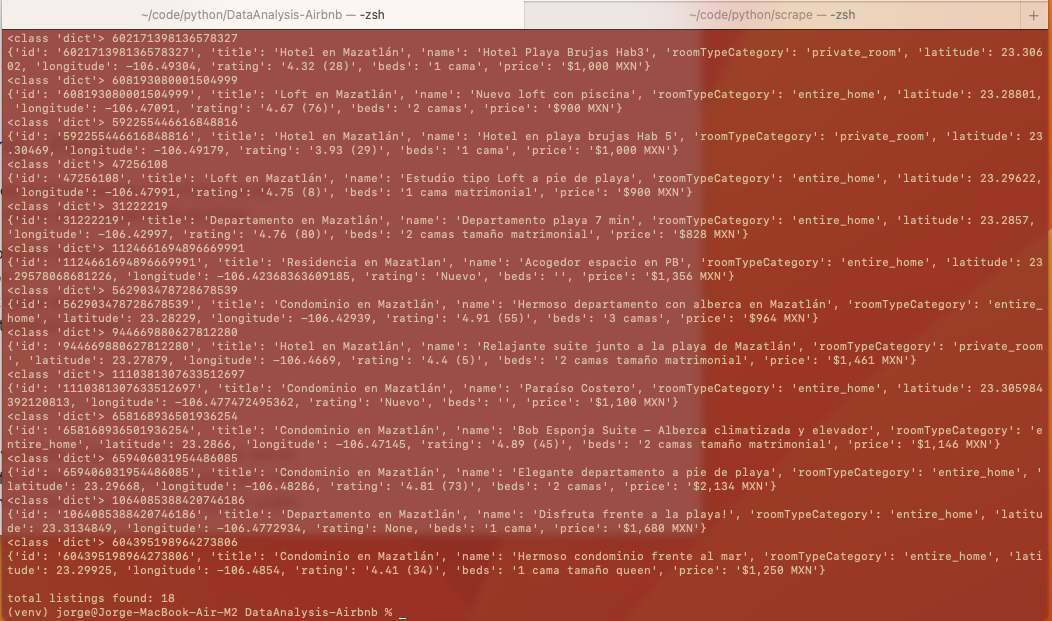
Así se ve el listing procesado a json:
Después de hacer el scraping completo de las 4 páginas base, se obtuvo un total de 1,692 registros, con los que haré Exploratory Data Analisys (EDA) en los siguientes posts, en los cuales inicialmente tendré que realizar las siguientes actividades:
- Ver que los acentos se vean correctamente cuando los cargue en un DataFrame
- estandarizar el campo roomTypeCategory
- separar los valores del campo rating (calificación y evaluaciones)
- análizar el campo de camas
- cambiar el valor de price a número
- analizar valores repetidos